Pull Requests are where good engineering habits either level up… or quietly get replaced by “LGTM, ship it.”
You open a PR. You do the responsible things:
- scan the diff,
- run tests,
- click the happy path,
- tell yourself you definitely didn’t miss anything important.
Then your reviewer asks:
What happens if the uploaded filename contains weird Unicode?
And you realize the truth we all share: PR reviews are human-scaled. Attackers are not.
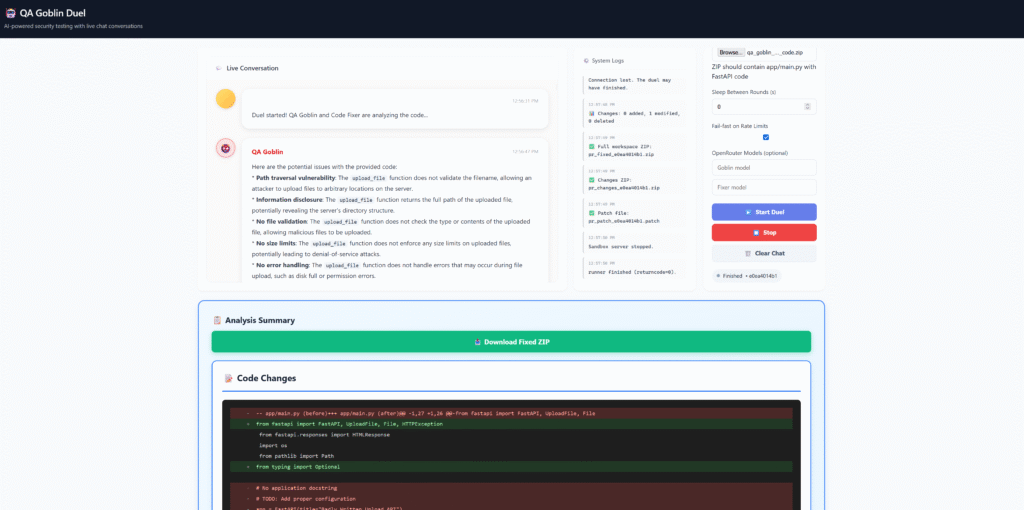
So I built QA Goblin Duel: an adversarial security testing + auto-fix framework for FastAPI code that runs like a PR review loop — except the reviewers are two AIs with opposite incentives:
- QA Goblin (malicious reviewer): tries to break the code with adversarial inputs.
- Code Fixer (defensive maintainer): proposes and applies minimal, reviewable patches.
- The system iterates in rounds until the suite goes green, and then it generates artifacts you can actually ship: full fixed ZIP, changes-only ZIP, unified patch, plus a report.
If you’re building developer tooling, it’s the most satisfying type of automation: the kind where you watch your PR “get reviewed” while you do literally anything else.
The real problem: PR reviews rarely test the “weaponized input” path
Most reviews optimize for:
- correctness (usually on the happy path),
- readability,
- maintainability,
- architecture alignment.
Security issues often hide in inputs that feel too annoying to test manually every PR:
- path traversal (including ZIP-slip patterns),
- content-type spoofing,
- null byte injection style payloads,
- double extensions (
.jpg.exe), - Unicode confusables / invisible characters,
- right-to-left override tricks in filenames,
- protocol edge cases.
The gap isn’t that teams don’t care. The gap is that manual adversarial testing does not scale.
So the core idea of QA Goblin Duel is simple:
Treat adversarial security testing like a PR review step — then automate the boring parts and keep the output reviewable.
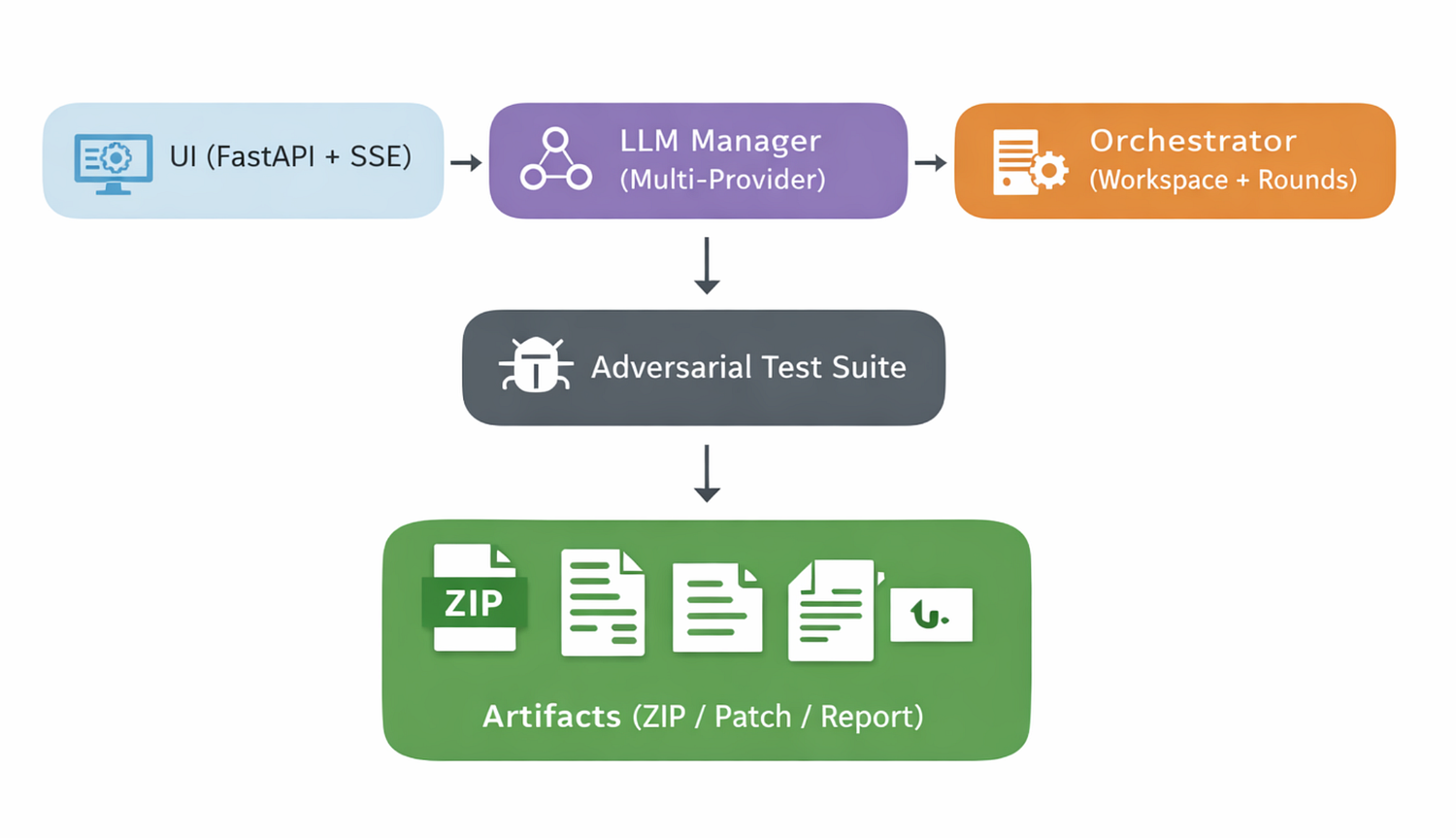
What the system does (end-to-end)
Input modes (two ways to use it)
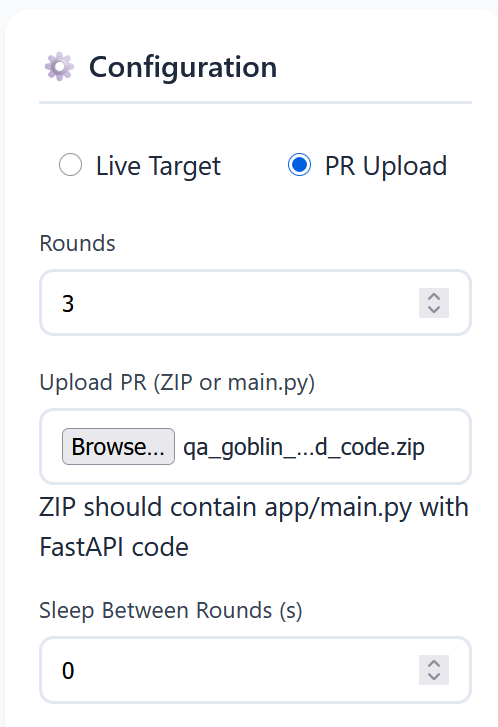
- PR Upload Testing (recommended for code review / CI)
You upload a ZIP containing a FastAPI app. The system:
- unpacks it into an isolated workspace,
- launches the app (or runs tests against it in-process),
- runs the adversarial suite,
- iterates fixes,
- generates downloadable artifacts.
2. Live Target Testing (useful for already-deployed services)
You point the Goblin at a running HTTP endpoint and it runs targeted adversarial checks (no code artifacts generated in this mode, but you still get findings + recommendations).
Why it’s a duel (and not “one AI that does everything”)
If you ask one model to “review and improve my PR,” you get one of two failure modes:
- Too polite: “Looks great!”
- Too enthusiastic: “I rewrote half your codebase and introduced 12 new abstractions.”
The duel design solves this by separating incentives:
- Goblin is rewarded for being ruthless, paranoid, and creative.
- Fixer is rewarded for being minimal, mergeable, and test-driven.
That tension is what makes it feel like a real review: one side pressures the code, the other side stabilizes it without turning it into a new project.
The project structure (so you can reproduce the layout)
qa-goblin-demo/
├── app/ # Example FastAPI app to test against
├── tools/qa_goblin/ # Core framework
│ ├── duel_ui.py # Web UI server (FastAPI + SSE)
│ ├── pr_duel.py # PR duel orchestrator (rounds, workspace)
│ ├── duel_groq.py # Live-target duel runner (optional mode)
│ ├── goblin.py # QA Goblin agent (prompting + orchestration hooks)
│ ├── goblin_hard.py # Adversarial security test suite
│ ├── llm_manager.py # Multi-provider routing + reliability layer
│ ├── workspace_diff.py # Snapshots + diffs + artifact packaging
│ ├── llm_groq.py # Provider client
│ ├── llm_openrouter.py # Provider client
│ └── llm_router.py # Shared routing utilities
├── scripts/ # Run UI, validate keys, cleanup, etc.
├── tests/ # Unit tests for manager/diff/UI
├── requirements.txt
├── README.md
└── TROUBLESHOOTING.md
This separation is intentional: UI, orchestration, testing, and LLM integration are independent. That’s what keeps the system extensible.
The execution flow (the part people can replicate)
Here’s the “PR Upload Testing” flow in a way an engineer can rebuild:
Step 1: Create an isolated workspace
Each run gets a unique workspace directory, e.g. workspaces/<run_id>/.
Key rules:
- Never run against the original ZIP directly.
- Treat the workspace as disposable.
- Exclude caches and virtualenvs from outputs (
__pycache__,.venv,.pytest_cache, etc.)
Step 2: Snapshot “before”
Before touching code, store a lightweight snapshot:
- a file manifest (paths + hashes),
- optionally a tar/zip of the pristine workspace.
This is the foundation for clean diffs later.
Step 3: Start the target app (or its test harness)
For FastAPI, the common approach is:
- run Uvicorn on a random available port,
- ensure it runs in a separate subprocess so your orchestrator remains stable,
- implement a health check loop (poll
/docs,/openapi.json, or/health).
Step 4: Run the adversarial test suite
The suite is not “unit tests.” It’s an attack-driven set of checks that hit endpoints (especially file upload / parsing endpoints) with payloads that simulate OWASP-style failures.
Examples of test categories:
- path traversal / ZIP-slip attempts,
- double extension payloads,
- null byte style payload patterns,
- Unicode confusables and normalization traps,
- RLO filename tricks (right-to-left override),
- content-type spoofing,
- protocol compliance checks (wrong headers, weird multipart boundaries, etc.)
Each test produces:
- pass/fail,
- a minimal reproduction (request summary),
- and a short “why this matters.”
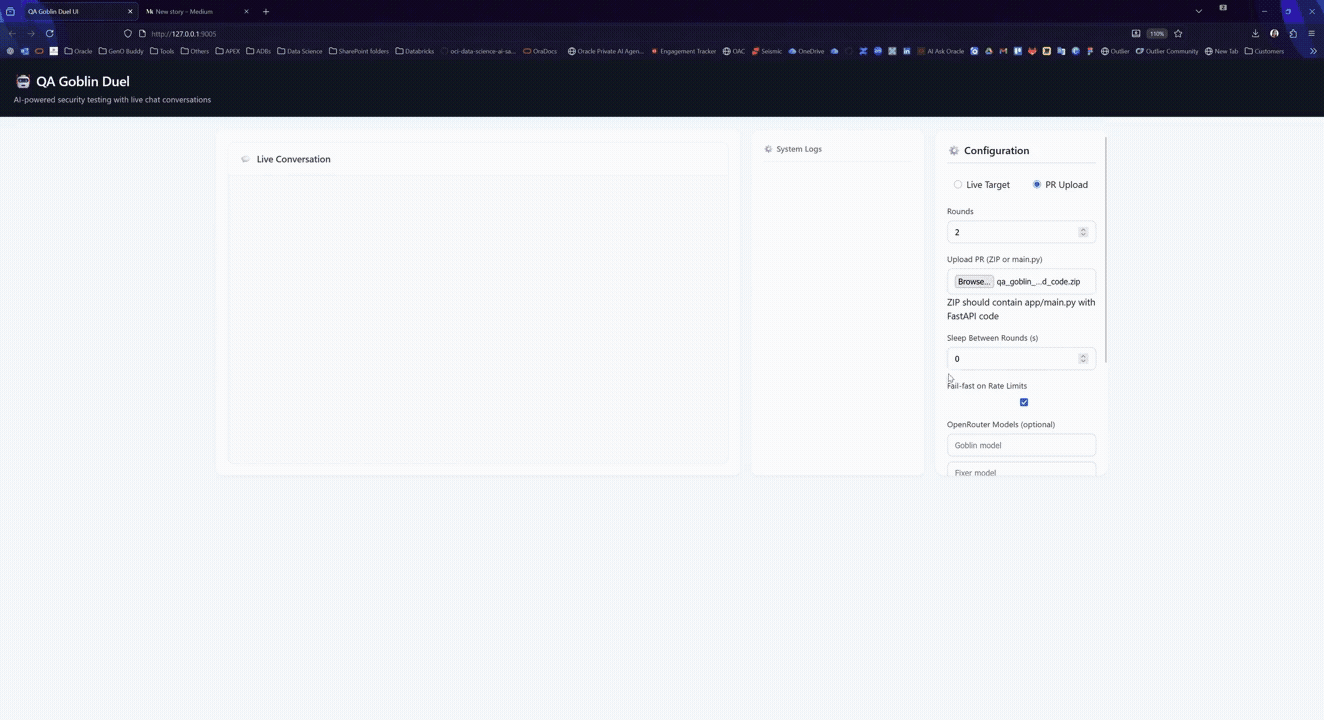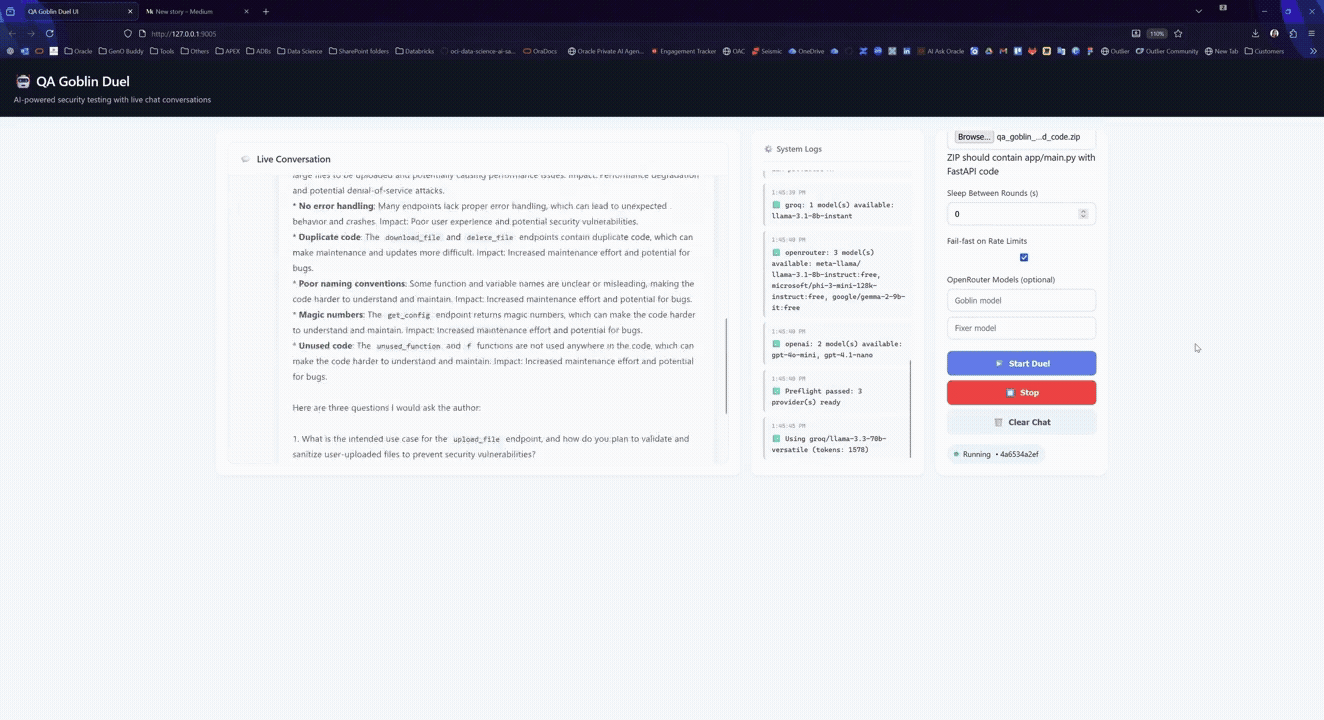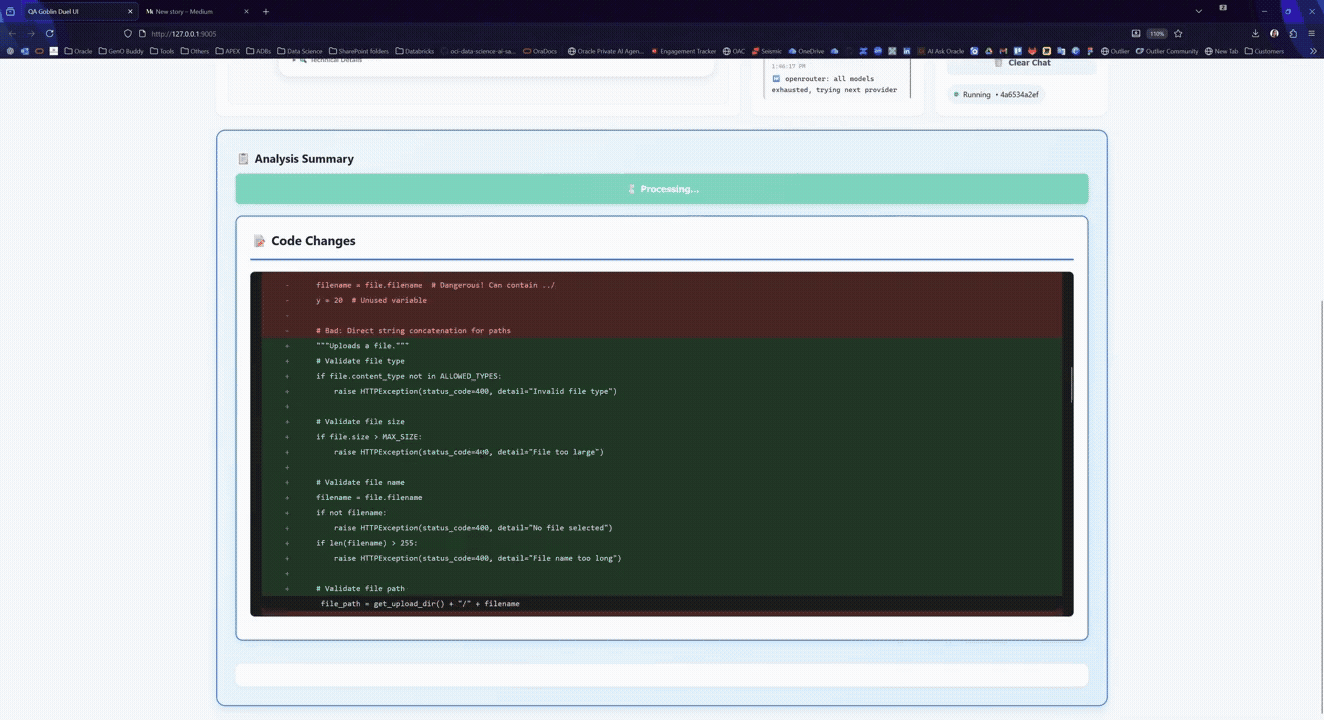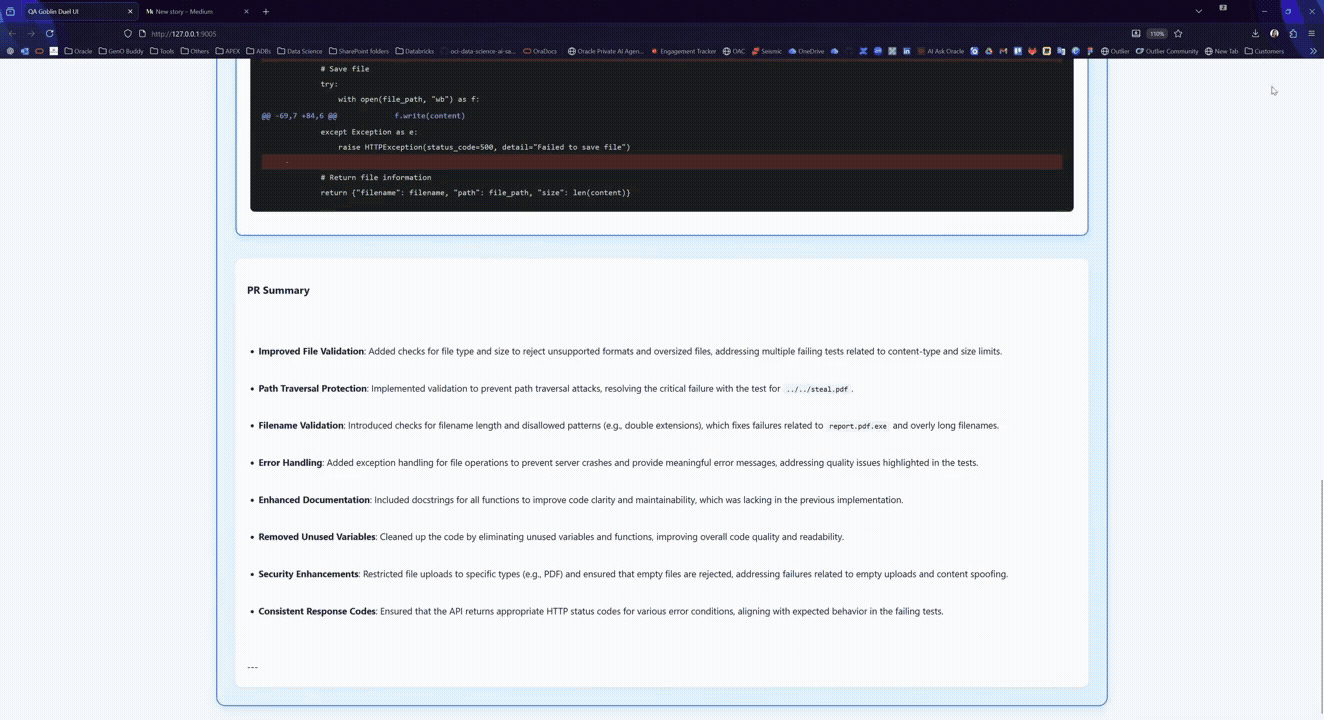
Step 5: When a test fails, trigger a duel round
A “round” is a strict loop:
- Goblin reads the failure context
- Goblin proposes an exploit narrative + what it expects is wrong

3. Fixer proposes a patch strategy

4. Fixer edits the workspace files

5. Rerun the failing tests (and ideally the whole suite)
6. Continue or stop
A practical stop condition:
- all tests pass, or
- you hit a round limit (e.g., 3–5 rounds).
Step 6: Snapshot “after,” generate artifacts
When done, generate:
- Unified patch (git-style diff): ideal for code review.
- Changes-only ZIP: only modified/added files + manifest.
- Full fixed ZIP: the complete workspace (cleaned).
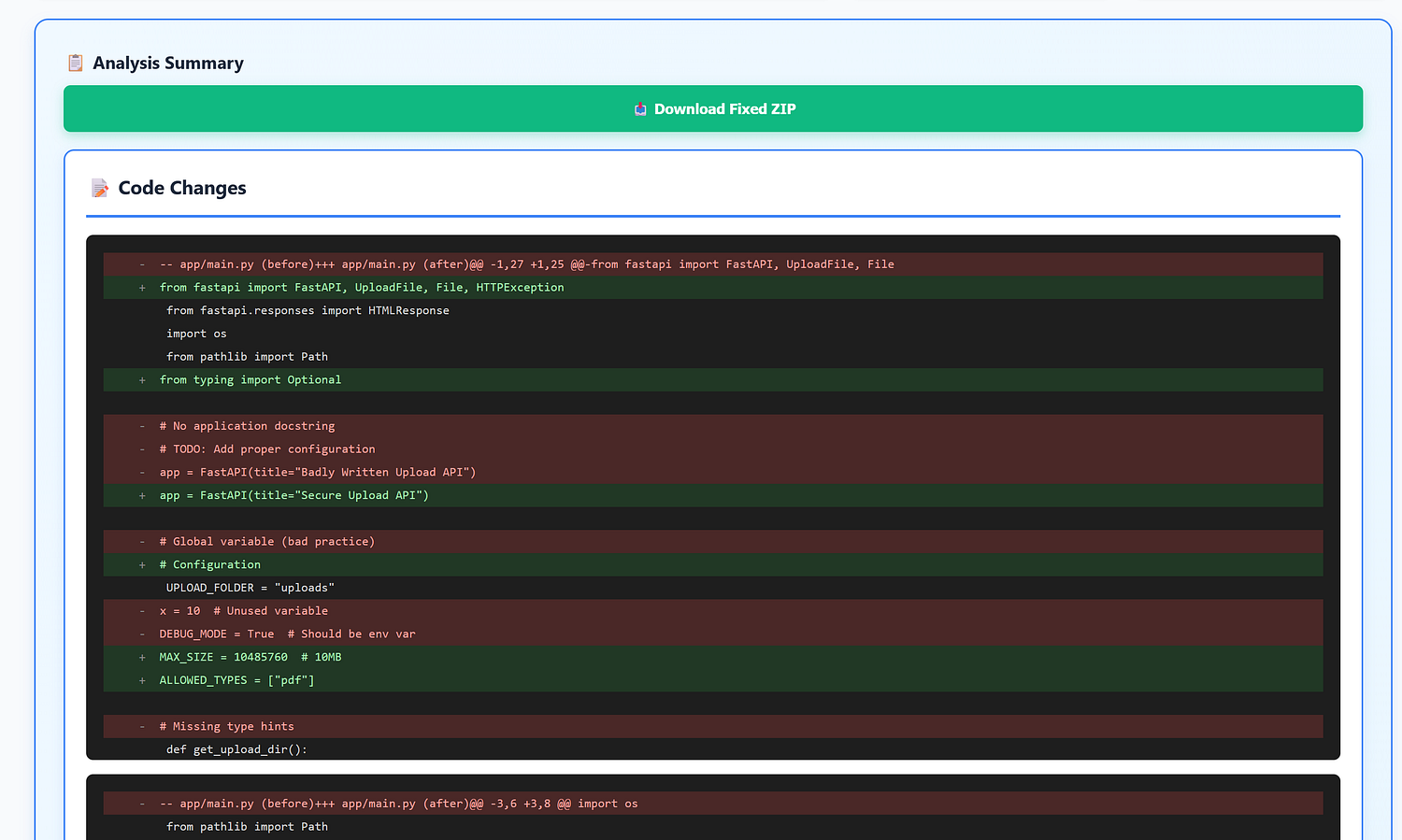
- Markdown report: results per test, with round-by-round commentary.
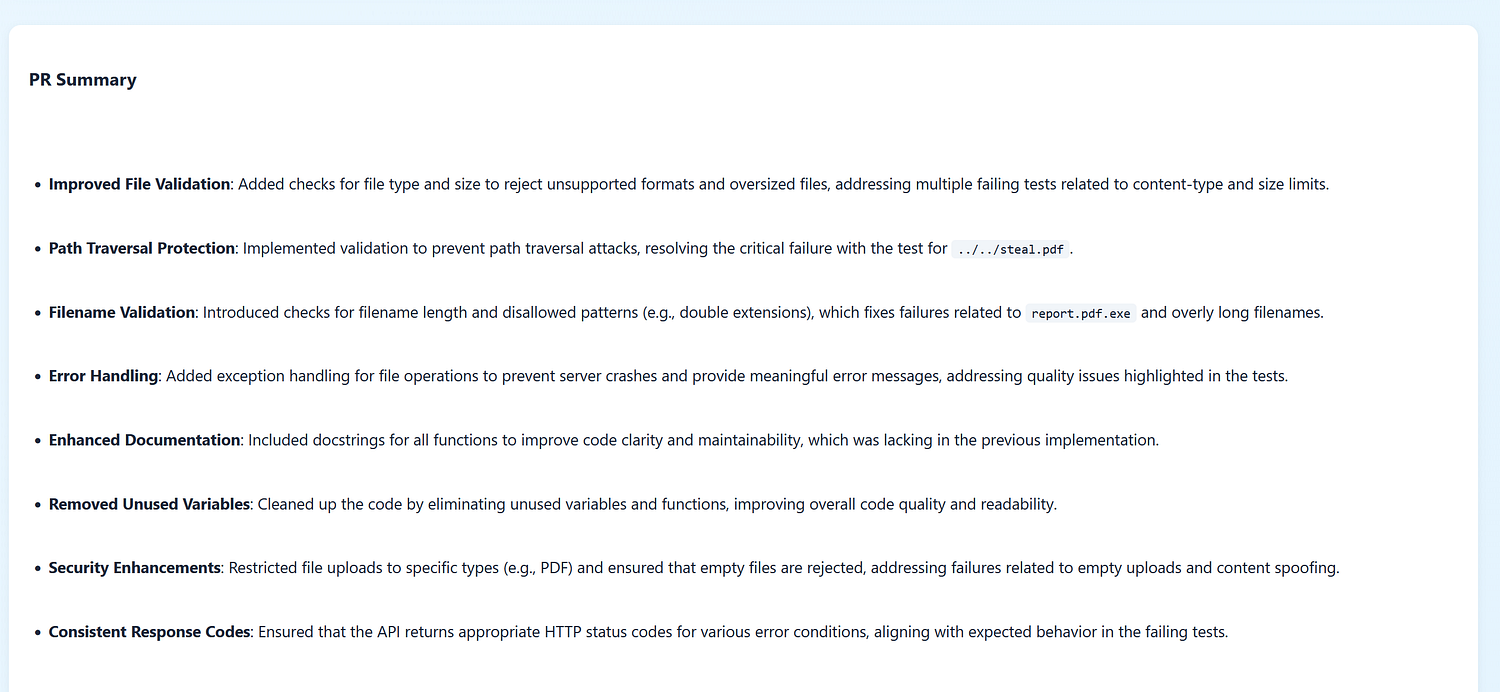
The “auto-fix” philosophy: mergeable changes or it doesn’t count
The Fixer is constrained like a real maintainer:
- prioritize minimal diffs,
- avoid refactors unless required to fix the issue,
- add explicit validation close to input boundaries,
- keep error messages actionable,
- prefer standard library / existing dependencies.
This matters because the output has to survive the real review step: a human reading the patch.
The UI: FastAPI + Server-Sent Events (SSE)
I wanted the UI to feel like watching a PR review conversation unfold in real time:
- streamed Goblin messages,
- streamed Fixer messages,
- explicit round boundaries,
- visible progress,
- and obvious download buttons at the end.
SSE is perfect for one-way streaming updates:
- simple on the backend,
- simple in the browser,
- no WebSocket complexity unless you truly need bidirectional interactivity.
The multi-provider LLM setup (how “free models” fit in, practically)
A major goal was: make it usable without committing to a paid LLM stack on day one, while still being resilient when providers rate-limit or models change.
The design is a provider-agnostic interface + a routing manager that supports:
- preflight checks (fail early if nothing is available),
- circuit breaker (stop calling a provider that’s currently failing),
- exponential backoff + jitter (recover gracefully from rate limits),
- fallback routing (try the next provider/model automatically),
- token usage tracking (so you can optimize prompts later).
A typical routing ladder might look like:
- Groq (fast, good for iteration)
- OpenRouter (broad model access, including free variants)
- Together (good as a stable paid fallback)
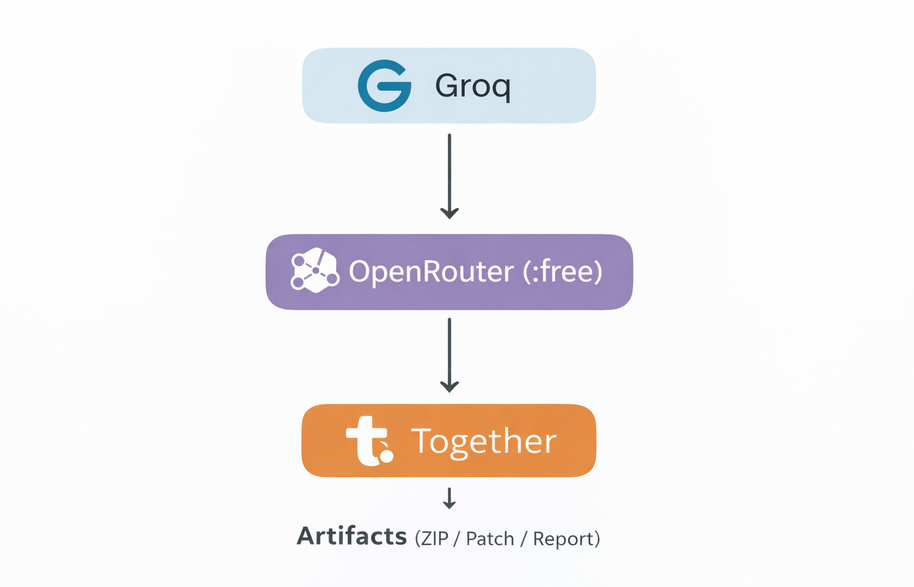
Even if someone chooses different models/providers, the pattern holds.
How to keep this reproducible
Two tips that make replication easier:
- Store API keys in local files that are gitignored (or environment variables).
- Make the model pool configurable via CLI flags so you can swap models without touching code.
Artifacts: the part that makes it feel like a PR tool
At the end of a successful run, you don’t want a wall of text. You want outputs that fit your workflow:
- Unified patch:
pr_patch_<run_id>.patch
Apply withgit applyor review like any PR diff. - Changes-only ZIP:
pr_changes_<run_id>.zip
Great for quick inspection and minimal download size. - Full fixed ZIP:
pr_fixed_<run_id>.zip
The whole workspace cleaned and packaged.
- Markdown report:
goblin_hard_pr_<run_id>.md
A readable “what happened” for audit and communication.
What I learned (the engineering reality list)
- Observability beats magic. If users can’t see what’s happening, they won’t trust the result.
- Tests must be the authority. Otherwise you’re just debating an LLM.
- Multi-provider routing isn’t fancy — it’s reliability engineering.
- Diffs are the social contract. Mergeability is the feature.
What I want to build next
This started as “a fun duel.” The practical roadmap is obvious:
- GitHub PR integration (comment on PRs + attach patches)
- Policy packs per domain (uploads/auth/parsers/payments)
- Historical comparison across runs (regression detection)
- Risk scoring per PR (not only pass/fail)
- Support for additional frameworks (Django, Express, etc.)
The goal is optimization and reproducibility. Not hype.
Responsible use
This tool is designed for security testing and education. Use it only on applications you own or have explicit permission to test.
Closing
If you enjoyed this post and you want more content about building practical AI tooling (the kind that survives rate limits, outages, and real developer workflows), follow me on my website, LinkedIn, and GitHub.
If you’re interested in QA Goblin Duel, I can share the project privately and I’m open to a conversation. Especially if you’re exploring PR automation, adversarial testing, or reliable multi-provider LLM architectures.
Happy coding!